Python是数据驱动的AI时代相当重要的一门编程语言,但是,目前绝大多数的Python课程都是从IT工程师的角度出发进行讲解,过多强调编程技巧,较少涉及统计分析中所需要关心的问题。本系列课程将基于统计学和数据分析需求出发,讲解如何基于Python完成数据获取、数据管理、统计分析、数据挖掘等工作。

共12套课程:
第一阶段:Python数据分析基础
《学习Pandas》
《玩转数据可视化》
《玩转统计分析》
第二阶段:Python统计建模与数据挖掘
《数据挖掘入门视频课程》
《玩转统计模型》
《学习数据挖掘》
第三阶段: Python文本挖掘与深度学习
《学习文本挖掘》
《深度学习》
第四阶段: 数据分析与挖掘行业案例
《客户流失分析》
《信用评分方法》
《推荐系统》
《欺诈检测》
视频截图:
视频截图:

课程目录:
├─第一阶段:Python数据分析基础
│ ├─Python数据分析系列视频课程–学习Pandas
│ │ 1-1 Why胖哒?
│ │ 1-2 Python常用IDE简介
│ │ 1-3 Anaconda的安装与配置
│ │ 1-4 Jupyter Notebook的基本操作
│ │ 10-1 配置Pandas绘图环境
│ │ 10-2 各类统计图的具体绘制(上)
│ │ 10-3 各类统计图的具体绘制(下)
│ │ 11-1 变量特征的基本描述
│ │ 11-2 分类变量的交叉表描述
│ │ 11-3 常用假设检验方法的实现
│ │ 12-1 数据准备
│ │ 12-2 了解数据的基本特征
│ │ 12-3 回答研究问题
│ │ 13-1 优化Pandas时的一些基本原则
│ │ 13-2 学习使用各种计时工具
│ │ 13-3 超大数据文件的处理
│ │ 13-4 加速!加速!再加速!
│ │ 13-5 如何进行多列数据的计算
│ │ 13-6 各种pandas加速外挂
│ │ 2-1 手工输入数据并建立数据框
│ │ 2-10 保存为SPSS数据文件【2020.3月新增】
│ │ 2-11 保存数据至数据库
│ │ 2-2 读取文本格式的数据文件
│ │ 2-3 读取EXCEL格式的数据文件
│ │ 2-4 读取统计软件的数据文件
│ │ 2-5 如何完美读取SPSS数据文件【2020.3月新增】
│ │ 2-6 读取数据库
│ │ 2-7 pandas数据读入保存命令总结【2020.3月新增】
│ │ 2-8 实战作业:读入PM2.5数据文件
│ │ 2-9 保存数据至外部文件
│ │ 3-1 对数据作简单浏览
│ │ 3-2 重命名变量列
│ │ 3-3 筛选变量列
│ │ 3-4 删除变量列
│ │ 3-5 变量类型的转换
│ │ 3-6 实战作业:对PM2.5数据做简单清理
│ │ 4-1 建立索引
│ │ 4-2 指定某列为索引
│ │ 4-3 将索引还原回列
│ │ 4-4 引用和修改索引
│ │ 4-5 强行更新索引
│ │ 5-1 案例排序[【2020.9月更新】
│ │ 5-2 按照实际位置进行筛选
│ │ 5-3 按照索引值进行筛选
│ │ 5-4 列表筛选与条件筛选【2020.9月更新】
│ │ 5-5 用类SQL语句筛选
│ │ 6-1 计算新变量(上)
│ │ 6-2 计算新变量(下)
│ │ 6-3 对应数值的替换
│ │ 6-4 指定数值范围的替换
│ │ 6-5 哑变量变换
│ │ 6-6 数值分段
│ │ 7-1 数据分组汇总【2020.9月更新】
│ │ 7-2 数据拆分【2020.9月更新】
│ │ 7-3 长形格式和宽形格式的互相转换
│ │ 7-4 数据的纵向合并
│ │ 7-5 数据的横向合并【2020.9月更新】
│ │ 7-6 concat命令介绍
│ │ 8-1 读入PM2.5实战案例数据
│ │ 8-2 缺失值的设定
│ │ 8-3 如何处理缺失值
│ │ 8-4 数据查重
│ │ 8-5 直接比较数据框变量列【2020.9月新增】
│ │ 9-1 建立Timestamp类
│ │ 9-2 将数据转换为Timestamp类
│ │ 9-3 使用DatetimeIndex类
│ │ 9-4 对时间序列做基本处理
│ │ Pandas10.pdf
│ │ Pandas11.pdf
│ │ Pandas12.pdf
│ │ Pandas13.pdf
│ │ Pandas2.pdf
│ │ Pandas3.pdf
│ │ Pandas4.pdf
│ │ Pandas6.pdf
│ │ Pandas8.pdf
│ │ Pandas9.pdf
│ │ Pandas作业10.zip
│ │ Pandas作业11.zip
│ │ Pandas作业5.zip
│ │ Pandas作业6.zip
│ │ Pandas作业7.zip
│ │ Pandas作业8.zip
│ │ Pandas作业9.zip
│ │ PythonPandasData202009.zip
│ │ 作业2.pdf
│ │ 作业4.zip
│ │
│ ├─Python数据分析系列视频课程–玩转数据可视化
│ │ 1-1 Python中的数据可视化工具介绍
│ │ 1-2 本课程的内容安排
│ │ 1-3 Python常用IDE简介
│ │ 1-4 Anaconda的安装与配置
│ │ 1-5 Jupyter Notebook的基本操作
│ │ 10-1 seaborn的样式管理
│ │ 10-2 打包加载seaborn样式
│ │ 10-3 设置坐标轴样式
│ │ 10-4 设置坐标轴刻度和刻度标签
│ │ 10-5 移动与控制坐标轴
│ │ 10-6 使用文字注解
│ │ 10-7 统计图表中的文字设定原则
│ │ 10-8 字体设定
│ │ 11-1 P-P图
│ │ 11-2 Q-Q图
│ │ 11-3 Pareto图
│ │ 11-4 人口金字塔
│ │ 11-5 雷达图
│ │ 11-6 复合饼图
│ │ 11-7 热图
│ │ 12-1 填充两个水平曲线间的区域
│ │ 12-2 填充密闭的多边形区域
│ │ 12-3 绘制各种常用多边形
│ │ 12-4 自由绘制多边形
│ │ 12-5 使用外部图片
│ │ 2-1 绘图操作1:设置Figure对象
│ │ 2-2 绘图操作2:用Plot函数绘图
│ │ 2-3 绘图操作3:设置图形格式
│ │ 2-4 绘图操作4:输出图形
│ │ 2-5 matplotlib+seaborn绘图环境设定
│ │ 3-1 统计图的基本信息维度
│ │ 3-2 统计图的基本框架
│ │ 3-3 展示单分类变量信息的统计图
│ │ 3-4 展示单连续变量信息的统计图
│ │ 3-5 双变量统计图:分类vs分类变量
│ │ 3-6 双变量统计图:含有数值变量
│ │ 3-7 展示多变量信息的统计图
│ │ 4-1 CCSS项目介绍
│ │ 4-2 简单条图
│ │ 4-3 饼图,半圆图与圆环图
│ │ 4-4 条带图
│ │ 4-5 直方图,KDE图与地毯图
│ │ 4-6 箱图与增强箱图
│ │ 4-7 提琴图
│ │ 5-1 带误差线的条图
│ │ 5-2 分组条图、堆积条图与百分条图
│ │ 5-3 用matplotlib绘制线图
│ │ 5-4 用seaborn绘制线图
│ │ 5-5 误差图与面积图
│ │ 6-1 普通散点图
│ │ 6-2 变量间的回归趋势考察
│ │ 6-3 复杂回归曲线的拟合
│ │ 6-4 考察回归残差的分布
│ │ 6-5 分组考察回归关系
│ │ 6-6 联合变量分布的散点图
│ │ 6-7 Hexbin图和等高线图
│ │ 6-8 散点图矩阵
│ │ 6-9 三维散点图
│ │ 7-1 设置图例
│ │ 7-2 混合图形与双轴图
│ │ 7-3 使用行列面板
│ │ 8-1 图形叠加和图中图
│ │ 8-2 用subplot命令绘制子图
│ │ 8-3 用subplots命令绘制子图
│ │ 8-4 调整子图间距
│ │ 8-5 复杂网格:subplot2grid方法
│ │ 8-6 复杂网格:Gridspec方法
│ │ 9-1 色彩搭配的基本原则
│ │ 9-2 如何自定义理想的色系
│ │ 9-3 色板的指定方式
│ │ 9-4 分类色板
│ │ 9-5 连续色板
│ │ 9-6 离散色板
│ │ Python数据可视化ch1.pdf
│ │ Python数据可视化ch10.pdf
│ │ Python数据可视化ch11.pdf
│ │ Python数据可视化ch2.pdf
│ │ Python数据可视化ch3.pdf
│ │ Python数据可视化ch4.pdf
│ │ Python数据可视化ch5.pdf
│ │ Python数据可视化ch6.pdf
│ │ Python数据可视化ch7.pdf
│ │ Python数据可视化ch8.pdf
│ │ Python数据可视化ch9.pdf
│ │ Python数据可视化Data.zip
│ │
│ └─Python数据分析系列视频课程–玩转统计分析
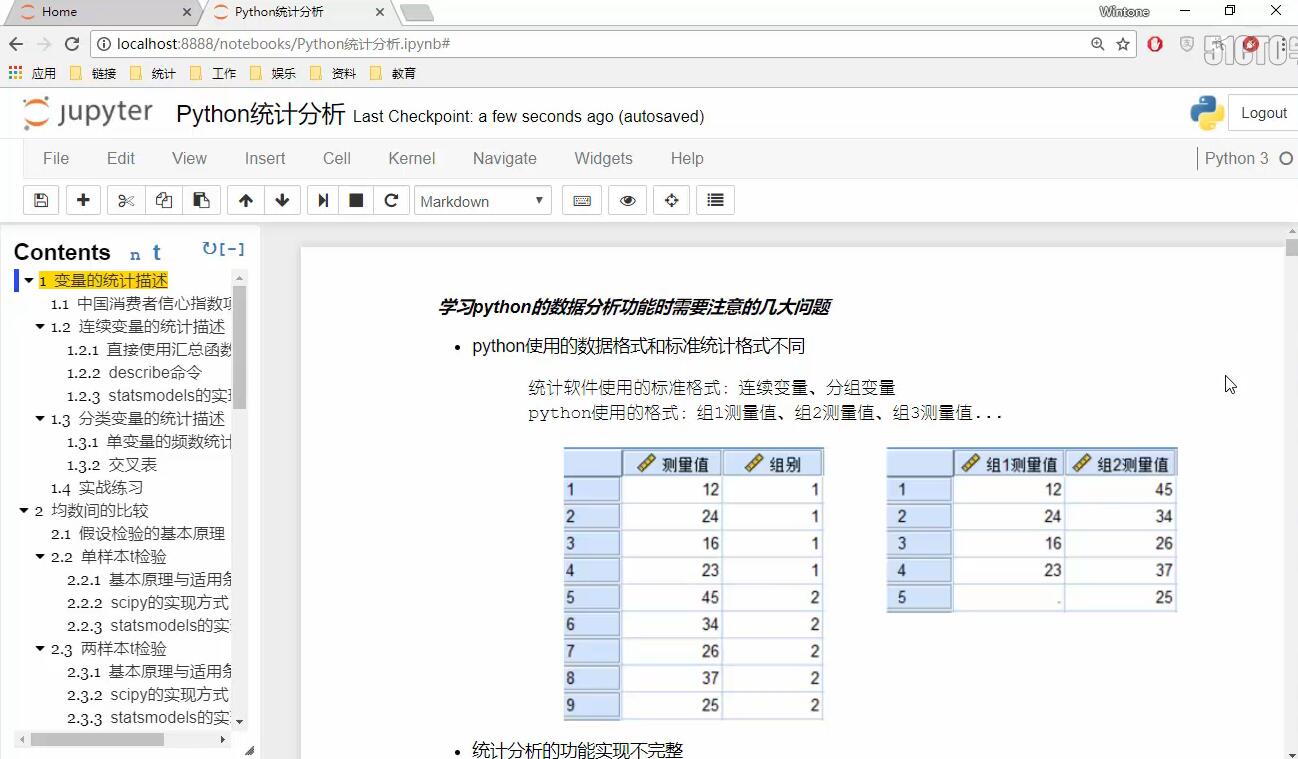
│ 1-1 学Python统计分析时要注意的几大问题
│ 1-2 中国消费者信心指数项目概况
│ 1-3 连续变量的统计描述(上)
│ 1-4 连续变量的统计描述(下)
│ 1-5 分类变量的频数描述
│ 1-6 分类变量的交叉表描述
│ 2-1 假设检验的基本原理
│ 2-10 配对t检验的基本原理
│ 2-11 配对t检验的python实现
│ 2-2 假设检验的基本步骤
│ 2-3 一类错误、二类错误与检验效能
│ 2-4 假设检验的注意事项
│ 2-5 单样本t检验的基本原理
│ 2-6 单样本t检验的python实现
│ 2-7 两样本t检验的基本原理
│ 2-8 两样本t检验的scipy实现
│ 2-9 两样本t检验的statsmodels实现
│ 3-1 案例独立性的考察
│ 3-2 正态性的图形考察
│ 3-3 正态性的假设检验考察
│ 3-4 正态性考察的python实现
│ 3-5 正态性不满足时的应对策略
│ 3-6 方差齐性的考察和应对策略
│ 3-7 方差齐性考察的python实现
│ 4-1 多组均数比较时面临的问题
│ 4-2 方差分析的基本原理
│ 4-3 单因素方差分析的python实现
│ 4-4 事后两两比较:直接校正检验水准
│ 4-5 事后两两比较方法的选择
│ 4-6 事后两两比较的python实现
│ 5-1 非参数统计分析方法的基本概念
│ 5-2 非参数统计分析方法的基本原理
│ 5-3 成组样本比较的非参数方法
│ 5-4 成组样本比较非参数方法的实现
│ 5-5 配对样本比较的非参数方法
│ 5-6 配对样本比较非参数方法的实现
│ 5-7 秩变换分析的基本原理
│ 5-8 秩变换分析方法的python实现
│ 6-1 卡方检验的基本原理
│ 6-2 卡方检验的scipy实现
│ 6-3 卡方检验statsmodels实现
│ 6-4 卡方检验的两两比较
│ 6-5 卡方校正与确切概率法
│ 6-6 配对卡方检验
│ 6-7 分层卡方检验
│ 6-8 二项分布检验的基本原理
│ 6-9 二项分布检验的python实现
│ 7-1 相关分析概述
│ 7-2 相关系数的计算原理
│ 7-3 相关分析的python实现
│ 7-4 OR和RR的基本概念
│ 7-5 OR和RR的python实现
│ 8-1 相关和回归的联系与区别
│ 8-2 线性回归模型概述
│ 8-3 线性回归模型的适用条件
│ 8-4 线性回归模型的标准建模步骤
│ 8-5 线性回归模型的scipy实现
│ 8-6 线性回归模型的statsmodels实现
│ 8-7 多变量回归模型与残差分析
│ 9-1 为什么要估计样本量
│ 9-2 样本量的计算原理
│ 9-3 t检验的样本量估计
│ 9-4 单因素ANOVA的样本量估计
│ 9-5 率的比较的样本量估计
│ CCSS_sample.zip
│ chap1.pdf
│ chap2.pdf
│ chap3.pdf
│ chap4.pdf
│ ex1.pdf
│ ex2.pdf
│ ex3.pdf
│ ex4.pdf
│ pythonstatchap5.pdf
│ pythonstatchap6.pdf
│ pythonstatchap7.pdf
│ pythonstatchap8.pdf
│ pythonstatchap9.pdf
│ pythonstatex5.pdf
│ pythonstatex6.pdf
│ pythonstatex7.pdf
│ pythonstatex8.pdf
│ pythonstatex9.pdf
│
├─第三阶段:Python文本挖掘与深度学习
│ ├─Python数据分析系列视频课程–学习文本挖掘
│ │ 1-1 什么是文本挖掘
│ │ 1-2 文本挖掘的基本流程和任务
│ │ 1-3 文本挖掘的基本思路
│ │ 1-4 语料数据化时需要考虑的工作
│ │ 10-1 情感分析概述
│ │ 10-2 情感分析的词袋模型实现
│ │ 10-3 情感分析的分布式表达实现
│ │ 11-1 自动摘要的基本原理
│ │ 11-2 自动摘要的效果评价
│ │ 11-3 自动摘要的python实现
│ │ 12-1 RNN的基本原理
│ │ 12-2 LSTM的基本原理
│ │ 12-3 Keras+TensorFlow组合的优势
│ │ 12-4 Keras+TensorFlow组合的安装
│ │ 12-5 案例1:数据准备
│ │ 12-6 案例1:模型拟合
│ │ 12-7 案例2:数据准备
│ │ 12-8 案例2:模型拟合
│ │ 2-1 Python常用IDE简介
│ │ 2-2 Anaconda的安装与配置
│ │ 2-3 Jupyter Notebook的基本操作
│ │ 2-4 NLTK的安装与配置
│ │ 2-5 什么是语料库
│ │ 2-6 准备《射雕》语料库
│ │ 3-1 分词原理简介
│ │ 3-2 结巴分词的基本用法
│ │ 3-3 使用自定义词典和搜狗细胞词库
│ │ 3-4 去除停用词
│ │ 3-5 词性标注及其他
│ │ 4-1 词频统计
│ │ 4-2 词云概述
│ │ 4-3 wordcloud包的安装
│ │ 4-4 绘制词云
│ │ 4-5 设置词云背景模板
│ │ 4-6 修改词云颜色
│ │ 5-1 词袋模型
│ │ 5-2 词袋模型的gensim实现
│ │ 5-3 用Pandas生成文档词条矩阵
│ │ 5-4 用sklearns生成文档-词条矩阵
│ │ 5-5 从词袋模型到N-gram模型
│ │ 5-6 文本信息的分布式表示
│ │ 5-7 共现矩阵
│ │ 5-8 NNLM模型的突破
│ │ 5-9 word2vec一出,满座皆惊
│ │ 6-1 关键词提取的基本思路
│ │ 6-2 TF-IDF 算法
│ │ 6-3 TF-IDF算法的jieba实现
│ │ 6-4 TF-IDF算法的sklearn实现
│ │ 6-5 TF-IDF算法的gensim实现
│ │ 6-6 TextRank算法
│ │ 7-1 主题模型概述
│ │ 7-2 主题模型的sklearn实现
│ │ 7-3 主题模型的gensim实现
│ │ 8-1 基本概念
│ │ 8-2 词条相似度:word2vec训练
│ │ 8-3 词条相似度:word2vec应用
│ │ 8-4 文档相似度的词袋模型实现
│ │ 8-5 doc2vec
│ │ 8-6 文档聚类
│ │ 9-1 文本分类概述
│ │ 9-2 朴素贝叶斯算法
│ │ 9-3 算法的sklearn实现
│ │ 9-4 算法的NLTK实现
│ │ PythonTMData202009.zip
│ │ TM10.pdf
│ │ TM11.pdf
│ │ TM12n.pdf
│ │ TM2.pdf
│ │ TM3.pdf
│ │ TM4.pdf
│ │ TM5.pdf
│ │ TM6.pdf
│ │ TM7.pdf
│ │ TM8.pdf
│ │ TM9.pdf
│ │ TMData1801101.zip
│ │ TMData190320.zip
│ │ TM作业10.pdf
│ │ TM作业11.pdf
│ │ TM作业12.pdf
│ │ TM作业5.pdf
│ │ TM作业6.pdf
│ │ TM作业7.pdf
│ │ TM作业8.pdf
│ │ TM作业9.pdf
│ │ 作业2.pdf
│ │ 作业3.pdf
│ │ 作业4.pdf
│ │
│ └─Python数据分析系列视频课程–深度学习
│ 1-1 深度学习?深在哪里?!
│ 1-2 课程内容介绍
│ 1-3 如何选择各类深度学习模型
│ 1-4 图像的数据表示
│ 1-5 图像与数据的互相转换
│ 1-6 MNIST数据集介绍
│ 1-7 CIFAR-10数据集介绍
│ 1-8 什么是张量?
│ 2-1 Python常用IDE简介
│ 2-2 Anaconda的安装与配置
│ 2-3 Jupyter Notebook的基本操作
│ 2-4 Keras+TensorFlow组合的优势
│ 2-5 Keras+TensorFlow组合的安装
│ 3-1 神经网络的基本原理
│ 3-2 神经网络原理的具体演示
│ 3-3 神经网络的算法实质
│ 3-4 神经网络的连接函数
│ 3-5 损失函数与凸函数
│ 3-6 控制模型复杂度:正则化
│ 3-7 损失函数的求解:梯度下降法
│ 3-8 损失函数的求解:自适应算法
│ 4-1 Keras的基本操作步骤
│ 4-2 Keras操作的常用命令
│ 4-3 IRIS分析实例
│ 4-4 模型的可视化
│ 4-5 模型的终止训练、保存与载入
│ 4-6 模型的修改
│ 4-7 将Keras与sklearn结合使用
│ 4-8 用Keras拟合MNIST案例
│ 5-1 什么是卷积?
│ 5-2 CNN的基本原理
│ 5-3 CNN网络的结构
│ 5-4 Keras中和CNN有关的层设定
│ 5-5 MNIST实例的CNN实现
│ 5-6 对CIFAR10案例拟合简单CNN模型
│ 5-7 对CIFAR10案例拟合复杂CNN模型
│ 6-1 缺少源数据对建模的影响
│ 6-2 定义所需的图像变换方法
│ 6-3 直接生成变换后的图像数据
│ 6-4 流式数据处理
│ 6-5 图像的缩放操作
│ 7-1 为什么需要迁移学习?
│ 7-10 Keras的函数式API
│ 7-11 在原模型的基础上继续训练
│ 7-2 LeNet和AlexNet
│ 7-3 VGG
│ 7-4 ResNet
│ 7-5 GoogleNet
│ 7-6 Xception、DenseNet和NasNet
│ 7-7 Keras提供的预训练模型
│ 7-8 直接应用原模型预测
│ 7-9 利用原模型对数据做预处理
│ 8-1 RNN的基本原理
│ 8-2 RNN的模型分类
│ 8-3 RNN相关的网络层定义
│ 8-4 用RNN拟合MNIST案例
│ 8-5 用RNN拟合IMDB案例
│ 9-1 LSTM的基本原理
│ 9-2 用LSTM拟合IMDB案例
│ 9-3 自动写作案例:数据准备
│ 9-4 自动写作案例:模型拟合
│ 9-5 GRU的基本原理
│ 9-6 用GRU拟合IMDB案例
│ 深度学习讲义.zip
│
├─第二阶段:Python统计建模与数据挖掘
│ ├─Python数据分析系列视频课程–学习数据挖掘
│ │ 1-1 如何用python做机器学习数据挖掘?
│ │ 1-2 课程内容介绍
│ │ 1-3 使用sklearn的样本数据集
│ │ 1-4 sklearn基本操作入门
│ │ 1.pdf
│ │ 10-1 用模型集成改进效果的基本思路
│ │ 10-2 投票分类器
│ │ 10-3 模型集成的基本原理
│ │ 10-4 Bagging方法
│ │ 10-5 随机森林
│ │ 10-6 Adaboost方法
│ │ 10-7 GBDT方法
│ │ 10.pdf
│ │ 2-1 连续变量的标准化
│ │ 2-2 考虑异常分布的标准化
│ │ 2-3 分类变量的预处理
│ │ 2-4 缺失值的填充
│ │ 2-5 生成多项式特征
│ │ 2-6 自定义转换器
│ │ 2.pdf
│ │ 3-1 特征筛选概述
│ │ 3-2 基于简单统计特征进行筛选
│ │ 3-3 基于统计误差进行筛选
│ │ 3-4 基于建模结果进行筛选
│ │ 3-5 数据降维与信息浓缩
│ │ 3.pdf
│ │ 4-1 回归类模型概述
│ │ 4-10 随机梯度下降回归
│ │ 4-2 回归类模型的种类
│ │ 4-3 线性回归的sklearn实现
│ │ 4-4 多项式回归
│ │ 4-5 岭回归的基本原理
│ │ 4-6 岭回归的实现
│ │ 4-7 LASSO回归与弹性网络
│ │ 4-8 最小角回归
│ │ 4-9 梯度下降法的基本原理
│ │ 5-1 类别预测模型概述
│ │ 5-2 类别预测模型的实现原理
│ │ 5-3 类别预测模型的种类
│ │ 5-4 logistic回归
│ │ 5-5 神经网络的基本原理
│ │ 5-6 神经网络的实现
│ │ 5-7 树模型的基本原理
│ │ 5-8 树模型的实现
│ │ 5-9 随机梯度下降分类
│ │ 5.pdf
│ │ 6-1 聚类分析概述
│ │ 6-2 聚类分析的种类
│ │ 6-3 K均值聚类
│ │ 6-4 BIRCH聚类
│ │ 6-5 DBSCAN聚类
│ │ 6.pdf
│ │ 7-1 类别预测模型的评价
│ │ 7-2 分类模型评价:混淆矩阵
│ │ 7-3 分类模型评价:准确率与召回率
│ │ 7-4 分类模型评价:结果的汇总
│ │ 7-5 分类模型评价:ROC曲线
│ │ 7-6 回归模型的评价
│ │ 7-7 聚类模型的评价
│ │ 7-8 与随机预测结果相比较
│ │ 7.pdf
│ │ 8-1 数据拆分方法概述
│ │ 8-2 二分法的sklearn实现
│ │ 8-3 交叉验证的sklearn实现(上)
│ │ 8-4 交叉验证的sklearn实现(下)
│ │ 8.pdf
│ │ 9-1 如何改进数据挖掘模型的效果
│ │ 9-2 参数的网格搜索
│ │ 9-3 参数的随机搜索
│ │ 9-4 验证曲线
│ │ 9-5 学习曲线
│ │ 9.pdf
│ │ PythonDMData.zip
│ │ PythonDMData202009.zip
│ │ sk4n.pdf
│ │
│ ├─Python数据分析系列视频课程–玩转统计模型
│ │ 1-1 课程内容介绍
│ │ 1-2 statsmodles基本操作入门
│ │ 1-3 使用sklearn的样本数据集
│ │ 1-4 sklearn基本操作入门
│ │ 1.pdf
│ │ 10-1 聚类分析概述
│ │ 10-2 聚类分析的方法分类
│ │ 10-3 聚类分析的注意事项
│ │ 10-4 K均值聚类
│ │ 10-5 均值偏移聚类
│ │ 10-6 层次聚类
│ │ 10-7 BIRCH聚类
│ │ 10-8 DBSCAN聚类
│ │ 10-9 聚类结果的验证
│ │ 10.pdf
│ │ 11 (1).pdf
│ │ 11-1 KNN的基本原理
│ │ 11-2 KNN分类的操作
│ │ 11-3 KNN回归与无监督KNN
│ │ 12-1 生存分析的基本概念
│ │ 12-2 生存率的计算与曲线绘制
│ │ 12-3 生存曲线的比较
│ │ 12-4 风险函数与风险比
│ │ 12-5 Cox模型的基本概念
│ │ 12-6 cox比例风险模型的实现
│ │ 12-7 生存分析中的分层变量
│ │ 12.pdf
│ │ 13-1 关联分析的基本概念
│ │ 13-2 关联分析的数据格式与结果格式
│ │ 13-3 Apriori算法的原理与实现
│ │ 13-4 Apriori算法分析实例
│ │ 13-5 FP-growth算法
│ │ 13-6 关联分析的参数调整与具体应用
│ │ 13-7 令人大开眼界的关联分析结果
│ │ 2-1 一般线性模型概述
│ │ 2-2 简单一般线性模型模型的拟合
│ │ 2-3 均数两两比较方法的选择
│ │ 2-4 均数两两比较的实现
│ │ 2-5 多因素方差分析模型的基本框架
│ │ 2-6 多因素方差分析的实现
│ │ 2-7 模型框架下的自定义检验
│ │ 2.pdf
│ │ 3-1 线性回归模型概述
│ │ 3-2 线性回归模型的适用条件
│ │ 3-3 线性回归模型的标准建模步骤
│ │ 3-4 线性回归模型的statsmodels实现
│ │ 3-5 残差分析
│ │ 3-6 回归模型的多变量筛选方法
│ │ 3-7 多变量筛选的具体操作
│ │ 3-8 最小角回归
│ │ 3-9 线性回归的sklearn实现
│ │ 3.pdf
│ │ 4-1 曲线直线化
│ │ 4-10 残差非独立的识别与处理
│ │ 4-11 自回归模型
│ │ 4-2 多项式回归
│ │ 4-3 强影响点的识别与处理
│ │ 4-4 稳健回归
│ │ 4-5 共线性的识别与处理
│ │ 4-6 岭回归
│ │ 4-7 LASSO回归与弹性网络
│ │ 4-8 方差不齐的识别与处理
│ │ 4-9 加权最小二乘法
│ │ 5-1 logistic回归模型的基本概念
│ │ 5-2 logistic回归模型的适用条件
│ │ 5-3 两分类logistic模型的statsmodels实现
│ │ 5-4 logistic回归模型中的检验方法
│ │ 5-5 哑变量的使用(上)
│ │ 5-6 哑变量的使用(下)
│ │ 5-7 多分类因变量的logistic回归模型
│ │ 5-8 logistic回归模型的sklearn实现
│ │ 5.pdf
│ │ 6-1 树模型的基本概念
│ │ 6-2 树模型的信息量计算
│ │ 6-3 树模型的各种算法
│ │ 6-4 树模型的sklearn实现
│ │ 6-5 随机森林
│ │ 6-6 Adaboost方法
│ │ 6-7 GBDT方法
│ │ 6.pdf
│ │ 7-1 神经网络的基本原理
│ │ 7-2 神经网络的算法实质
│ │ 7-3 神经网络的sklearn实现
│ │ 7-4 RBFN、RNN、LSTM与与CNN网络
│ │ 7-5 SOM与RBM网络
│ │ 7-6 神经网络的超参数调整
│ │ 7.pdf
│ │ 8-1 SVM的基本原理
│ │ 8-2 SVM的核函数设定
│ │ 8-3 SVM分类
│ │ 8-4 SVM回归
│ │ 8-5 异常值检测的基本理论
│ │ 8-6 一类SVM
│ │ 8-7 模型参数的优化
│ │ 8.pdf
│ │ 9-1 主成分分析的基本原理
│ │ 9-2 主成分分析的statsmodels实现
│ │ 9-3 主成分分析的sklearn实现
│ │ 9-4 因子分析的基本原理
│ │ 9-5 因子分析的statsmodels实现
│ │ 9-6 因子旋转
│ │ 9.pdf
│ │ pymodel4n.pdf
│ │ PythonModelData.zip
│ │ PythonModelData190920.zip
│ │
│ └─数据挖掘入门视频课程
│ 1-1 为什么会出现数据挖掘技术?
│ 1-2 数据挖掘存在的价值
│ 1-3 数据挖掘究竟是什么?
│ 1-4 数据挖掘考虑解决的问题
│ 1-5 对数据挖掘的常见误解
│ 1-6 什么是大数据?
│ 2-1 CRISP-DM概述
│ 2-2 CRISP-DM之商业理解
│ 2-3 CRISP-DM中的其余细节问题
│ 3-1 统计模型概述
│ 3-2 统计模型的分类(上)
│ 3-3 统计模型的分类(下)
│ 3-4 别忘了统计描述也是战斗力!
│ 4-1 回归类模型概述
│ 4-2 回归类模型的方法框架
│ 4-3 类别预测模型概述
│ 4-4 类别预测模型的实现原理
│ 4-5 类别预测模型的方法框架
│ 4-6 聚类分析概述
│ 4-7 聚类模型的方法框架
│ 4-8 主成分分析与因子分析
│ 4-9 关联分析与序列分析
│ 5-1 文本挖掘概述
│ 5-2 TM工具:SAS_TM
│ 5-3 TM工具:Modeler
│ 5-4 TM工具:R
│ 5-5 TM工具:Python
│ 6-1 数据挖掘项目效果的评估
│ 6-2 类别预测模型的效果评价
│ 6-3 聚类模型的评价
│ 6-4 如何改进模型结果
│ 6-5 数据挖掘项目失败的原因
│ 7-1 数据挖掘软件概述
│ 7-2 SAS_EM简介
│ 7-3 SAS_EM操作入门
│ 7-4 Modeler简介
│ 7-5 Modeler的基本操作
│ 7-6 数据挖掘编程工具简介
│ 7-7 R数据挖掘操作入门
│ 7-8 sklearn数据挖掘操作入门
│ SPSS中级数据.zip
│
└─第四阶段:数据分析与挖掘行业案例
├─Python数据分析行业案例课程–信用评分方法
│ 1-1 信用评分课程介绍
│ 1-2 银行业务概述
│ 1-3 信用体系与信用风险
│ 1-4 从信用评分到评分卡
│ 1-5 A、B、C评分卡
│ 1-6 信用评分中需要考虑的因素
│ 10-1 得到初步的分箱结果
│ 10-2 箱体的自动合并
│ 10-3 将分箱值批量转换为WOE值
│ 11-1 删除低VI值或箱体比例超标变量
│ 11-2 【补课】共线性的识别与处理
│ 11-3 删除共线性变量
│ 11-4 【补课】树模型的基本原理
│ 11-5 【补课】树模型的各种算法
│ 11-6 【补课】随机森林方法
│ 11-7 用随机森林做变量初筛
│ 12-1 建模前需要考虑的问题
│ 12-2 【补课】logistic回归模型的sklearn实现
│ 12-3 手动筛选变量并建模
│ 12-4 【补课】控制模型复杂度:正则化
│ 12-5 【补课】模型参数的网格搜索
│ 12-6 建模并搜索优化惩罚值
│ 2-1 如何定义坏样本
│ 2-2 如何建立评分卡模型
│ 3-1 数据理解与数据准备
│ 3-2 数据不平衡问题
│ 4-1 分箱操作概述
│ 4-2 分箱的注意事项
│ 4-3 无监督分箱的代码实现
│ 4-4 Best KS法与卡方分箱法
│ 4-5 卡方分箱法的代码实现
│ 4-6 WOE与IV值
│ 4-7 WOE与IV的代码实现
│ 4-8 银行案例变量分箱的具体实现
│ 5-1 【补课】logistic回归模型的基本概念
│ 5-2 【补课】logistic回归模型的适用条件
│ 5-3 【补课】两分类logistic模型的代码实现
│ 5-4 银行案例的具体建模操作
│ 6-1 如何将概率转换为分值
│ 6-2 评分卡分值的具体计算
│ 6-3 如何对评分卡分值进行分段
│ 6-4 计算预期违约率
│ 7-1 模型验证(评价)与模型监控
│ 7-2 模型区分度的衡量指标
│ 7-3 模型准确度的衡量指标
│ 7-4 模型稳定性的衡量指标
│ 7-5 评分卡模型的部署
│ 7-6 评分卡的使用:准入与拒绝
│ 7-7 授信额度与利率定价的计算
│ 7-8 拒绝推断问题
│ 8-1 什么是互联网金融
│ 8-2 内部与外部数据源
│ 8-3 互联网金融案例的具体情况
│ 8-4 数据字典的应用价值
│ 8-5 本案例的特殊性
│ 9-1 特征工程概述
│ 9-2 【补课】数据的探索性分析:概述
│ 9-3 【补课】数据的探索性分析:代码实现
│ 9-4 数据衍生的基本思路
│ 9-5 基于时间窗口的指标衍生:代码实现
│ 9-6 具体的变量衍生操作
│ 9-7 缺失值处理的基本概念
│ 9-8 缺失值处理的代码实现
│ 9-9 分类变量的数值化
│ 案例:信用评分Data202009.zip
│
├─Python数据分析行业案例课程–客户流失分析
│ 1-1 流失分析课程介绍
│ 1-2 希望回答的商业问题
│ 1-3 流失可能和哪些因素相关
│ 1-4 如何定义时间窗口与挽留收益
│ 2-1 数据理解与数据准备阶段要做的工作
│ 2-10 缺失值的处理
│ 2-11 特征筛选
│ 2-12 数据衍生的基本思路
│ 2-13 本案例数据准备的具体操作
│ 2-2 数据源概况
│ 2-3 特征工程概述
│ 2-4 对案例的数据探索:概述
│ 2-5 对案例的数据探索:代码实现
│ 2-6 极端值与异常值的处理
│ 2-7 连续特征的处理思路
│ 2-8 连续特征的分箱
│ 2-9 分类特征的处理
│ 3-1 如何选择分析模型
│ 3-10 用神经网络计算流失评分
│ 3-11 【补课】模型参数的网格搜索
│ 3-12 神经网络的参数调优
│ 3-2 【补课】聚类分析概述
│ 3-3 【补课】聚类分析的方法框架
│ 3-4 用聚类做客户群体细分
│ 3-5 【补课】树模型的基本原理
│ 3-6 【补课】树模型的各种算法
│ 3-7 用树模型生成流失规则
│ 3-8 【补课】神经网络的基本原理
│ 3-9 【补课】神经网络原理的具体演示
│ 4-1 从模型结果到营销预演
│ 4-2 营销预演的代码实现
│ 4-3 流失分析进一步的改进方向
│ 5-1 银行业务的一些基本概念
│ 5-2 流失分析对银行业务的价值
│ 6-1 内部与外部数据源
│ 6-2 数据字典的应用价值
│ 6-3 银行数据的预处理
│ 6-4 银行数据的变量衍生
│ 6-5 第三方数据的预处理
│ 6-6 数据源的合并
│ 7-1 【补课】GBDT方法介绍
│ 7-2 GBDT模型的应用
│ 7-3 GBDT调优:调节模型整体参数
│ 7-4 GBDT调优:单棵树参数与综合调优
│ 7-5 【补课】模型集成的基本原理
│ 7-6 多种模型的联合应用
│ 案例:流失分析Data.zip
│
├─Python数据分析行业案例课程–推荐系统
│ 1-1 课程内容介绍
│ 1-2 为什么会出现推荐系统?
│ 1-3 推荐系统的常见形式
│ 1-4 推荐系统算法的基本思路
│ 1-5 推荐系统评测的三大步骤
│ 1-6 怎样才能算一个好的推荐系统?
│ 1-7 推荐系统的评估:准确率
│ 1-8 推荐系统的评估:其余指标
│ 10-1 冷启动概述
│ 10-2 用户冷启动的实现案例
│ 10-3 物品冷启动的实现案例
│ 2-1 推荐系统常用的相似度指标
│ 2-2 推荐系统中的一些基础模型
│ 2-3 电影评分数据集简介
│ 2-4 云音乐数据集简介
│ 2-5 云音乐数据集的预处理
│ 3-1 Surpise包简介
│ 3-2 Surpise包实战:读取数据
│ 3-3 Surpise包实战:数据拆分
│ 3-4 Surpise包实战:模型的拟合与评估
│ 3-5 Surpise包实战:将结果用于推荐
│ 4-1 协同过滤概述
│ 4-2 ItemCF方法
│ 4-3 UserCF方法
│ 4-4 【复习】KNN的基本原理
│ 4-5 ML100k案例:筛选算法框架
│ 4-6 ML100k案例:模型参数调优
│ 4-7 ML100k案例:将结果用于推荐
│ 5-1 【复习】主成分分析的基本原理
│ 5-2 SVD的基本原理
│ 5-3 如何将SVD用于推荐系统
│ 5-4 SVD++与NMF简介
│ 5-5 ML1m案例
│ 6-1 CB类方法的基本原理
│ 6-2 【复习】词袋模型
│ 6-3 【复习】用sklearn生成文档-词条矩阵
│ 6-4 ML案例:基于词频矩阵实现
│ 6-5 【复习】关键词提取的基本思路
│ 6-6 【复习】TF-IDF算法
│ 6-7 ML案例:基于TF-IDF实现
│ 7-1 如何将文本挖掘技术和内容推荐相结合
│ 7-10 【复习】NNLM模型的突破
│ 7-11 【复习】word2vec一出,满座皆惊
│ 7-12 【复习】文档相似度的doc2vec实现
│ 7-13 云音乐案例:基于词向量模型进行推荐
│ 7-2 【复习】分词原理简介
│ 7-3 【复习】结巴分词的基本用法
│ 7-4 【复习】使用自定义词典和搜狗细胞词库
│ 7-5 【复习】去除停用词
│ 7-6 云音乐案例:基于词袋模型进行推荐
│ 7-7 【复习】从词袋模型到N-gram模型
│ 7-8 【复习】文本信息的分布式表示
│ 7-9 【复习】共现矩阵
│ 8-1 如何基于列表序列进行推荐
│ 8-2 【复习】关联分析的数据格式与结果格式
│ 8-3 【复习】Apriori算法的原理与实现
│ 8-4 云音乐案例:基于关联分析进行推荐
│ 8-5 【复习】词条相似度:word2vec训练
│ 8-6 【复习】词条相似度:word2vec应用
│ 8-7 云音乐案例:基于词向量模型进行推荐
│ 9-1 【复习】聚类分析概述
│ 9-2 【复习】聚类分析的方法分类
│ 9-3 【复习】BIRCH聚类
│ 9-4 聚类分析在推荐系统中的应用思路
│ 9-5 云音乐案例:数据准备
│ 9-6 云音乐案例:具体建模操作
│ 案例:推荐系统Data202009.zip
│
└─Python数据分析行业案例课程–欺诈检测
1-1 欺诈检测课程介绍
1-2 欺诈检测的一些基本概念
1-3 欺诈检测的难点所在
1-4 欺诈检测模型和信用评分模型的差异
1-5 欺诈检测的三种分析思路
2-1 医疗保险欺诈案例概况
2-10 结合业务背景对案例做数据理解
2-2 数据理解与数据准备阶段要做的工作
2-3 特征工程概述
2-4 【复习】对案例的数据探索:概述
2-5 【复习】对案例的数据探索:代码实现
2-6 【复习】极端值与异常值的处理
2-7 连续特征的处理思路
2-8 分类特征的处理思路
2-9 数据衍生的基本思路
3-1 模型0:异常值发现
3-2 【复习】SVM的基本原理
3-3 【复习】异常值检测的基本理论
3-4 【复习】用单类SVM完成新奇值发现
3-5 异常值发现的代码实现
3-6 模型1:通过变量间的对比发现疑似欺诈
4-1 【复习】聚类分析概述
4-2 【复习】聚类分析的方法分类
4-3 【复习】K-means聚类
4-4 什么是Benford定律
4-5 模型2:通过Benford定律发现疑似欺诈
4-6 模型3:通过对投保人细分发现疑似欺诈
4-7 投保人细分发现欺诈的实现
4-8 模型4:发现医疗保健机构行为模式异常
5-1 模型5:发现多个医疗保健机构共用投保人信息
5-2 【复习】关联分析的基本概念
5-3 【复习】关联分析的数据格式与结果格式
5-4 【复习】Apriori算法的原理与实现
5-5 发现共用投保人信息的代码实现
5-6 模型6:发现异常诊断与处理过程
5-7 发现异常诊断和处理过程的代码实现
6-1 PaySim案例简介
6-10 【复习】数据不平衡问题
6-11 对数据进行加权处理后建模
6-2 PaySim案例的数据理解
6-3 PaySim案例的数据准备
6-4 【复习】类别预测模型概述
6-5 【复习】类别预测模型的实现原理
6-6 【复习】类别预测模型的种类
6-7 【复习】树模型的基本原理
6-8 【复习】随机森林
6-9 直接用随机森林建模
案例:欺诈检测Data202009.zip